Nomos: Haladir's Framework and Platform for Decisional Intelligence

Introduction
We at Haladir have maintained that the next era of logistics technology will be defined by formalizing the decisions that have never been formalized before. The techniques that become available once an operation has been properly formalized, such as mathematical optimization and simulation, have each existed for years or decades, but the formal models they depend on have always been built by hand during implementation projects, validated against conditions that existed at the time, and maintained only when something breaks visibly enough to justify another engagement. The objective functions, constraints, and data semantics that govern what a solver is actually optimizing are almost always static artifacts describing a version of the business that no longer exists. As the operation evolves around them, the gap between what is formally optimal and what is operationally sensible widens steadily until the system's recommendations lose the trust of the people who are supposed to act on them.
AI changes this because it can take the messy, unstructured reality of how an operation works and continuously translate it into the formal representations that these techniques require as input, which means the formalization itself can finally keep pace with the operation it describes. Haladir Nomos is the framework we have built around this principle, with AI performing continuous maintenance of the formal structure across five stages: data infrastructure, process intelligence, models and optimization, implementation, and monitoring and observability. What follows is a description of what each stage does and why they matter.
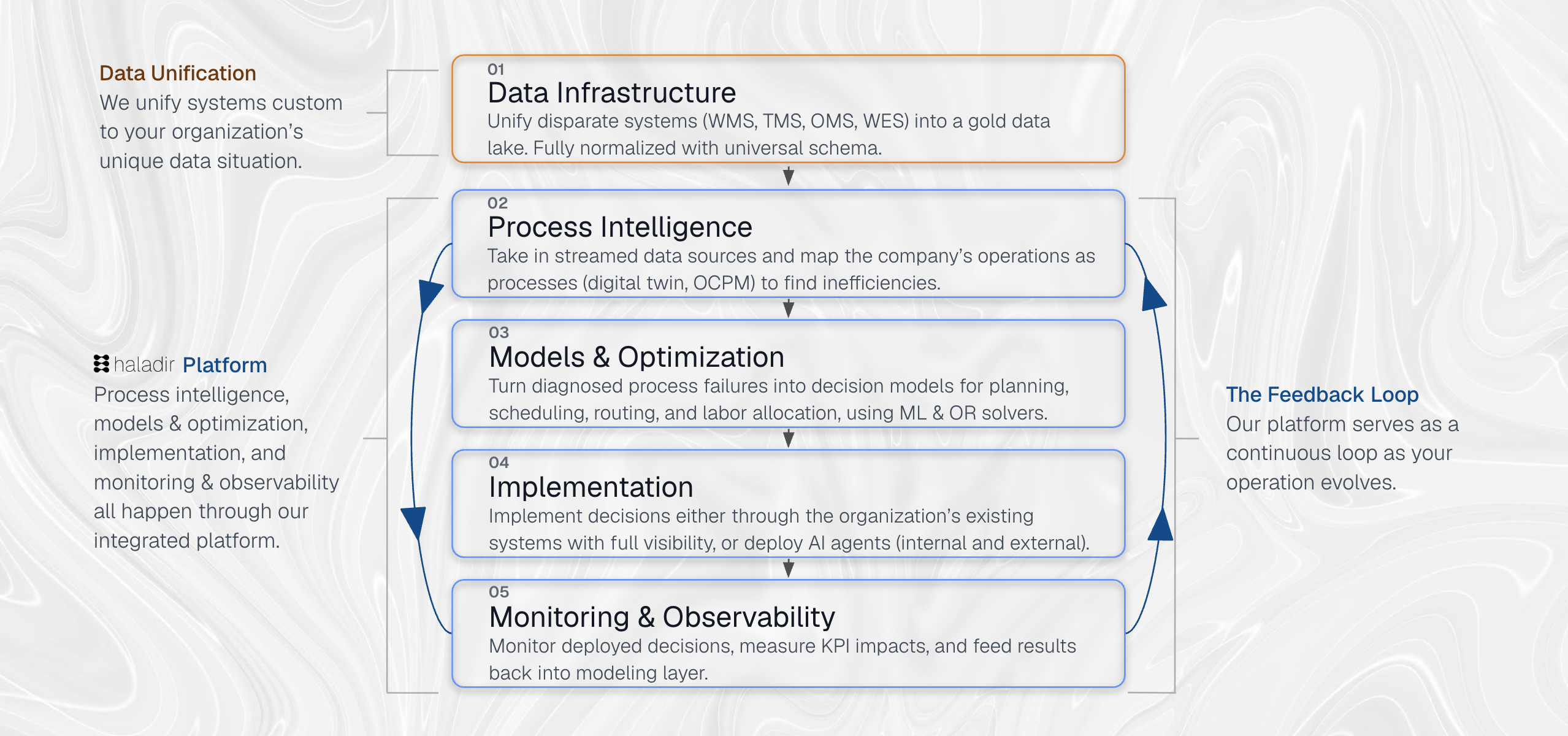
Data Infrastructure
The first stage of Nomos is data unification, and it is foundational in the sense that every other stage of the framework depends entirely on what this one produces. The same operational object, whether a shipment, an order, or a pallet, lives in fragments across many systems with different identifier conventions, timestamp formats, and event semantics. An order in the OMS becomes a delivery in the WMS, a load in the TMS, a milestone in a visibility platform, and an EDI 856 to a trading partner, and none of these representations fully reconcile on what to call the object or what state it is in. Partial reconciliation does exist through EDI standards and middleware layers, but it tends to be point-to-point and transaction-specific rather than holistic, which means that any given system has a defensible view of the object from its own perspective while no single system holds a complete picture of what actually happened to it across its full lifecycle.
Operations teams have always papered over this fragmentation with spreadsheets and the assumption that the planner at the screen will mentally stitch the fragments together, and that assumption holds reasonably well when humans are the ones making decisions, because a person looking at conflicting records from two systems can recognize the conflict and compensate for it. Importantly, however, that assumption does not extend to automated decision-making, because a solver does exactly what it has been told to do with exactly the data it has been given, and if that data is fragmented or inconsistent, the solver has no capacity to notice, no instinct to question its inputs, and no way to compensate. It will produce an answer that is mathematically optimal against the information it received, and confidently wrong in the context of the actual operation.
This fragmentation problem is compounded by a subtler one that is arguably harder to detect because it accumulates gradually rather than appearing as an obvious inconsistency. Operational data is full of semantic definitions that appear stable but shift without announcement. A field labeled "lead time" might blend transit time, administrative delay, and customs clearance into a single number whose composition has changed over the years as the operation evolved, without anyone updating the field's definition to reflect what it actually contains. Every downstream model consuming that field inherits an assumption about what it means that may no longer be true, and because the field still looks like a number in the expected range, there is no obvious signal that anything has gone wrong until the decisions built on top of it start producing outcomes that nobody can explain. The data infrastructure stage exists to make the operation legible as a unified whole, reconciling the fragments into a single coherent representation of the objects the operation actually works with while preserving the full history of how those objects changed over time, and continuously surfacing places where the data's stated definitions and the operation's actual behavior have diverged so that everything downstream remains correctable rather than silently wrong.
Process Intelligence
Unified data, no matter how complete and clean, tells you what happened to each operational object across its lifecycle but not the operational logic that produced those events. The structure of the workflows themselves, the constraints that shaped them, the dependencies between parallel processes, and the points where actual behavior has diverged from designed behavior all remain implicit in the event record. Process intelligence works backward from this evidence to reconstruct that structure, because it is the structure of the operation, its real constraints and dependencies and decision points, that a solver downstream requires as input in order to produce decisions that account for the way the operation actually runs.
This operational logic, however, does not exist in any single place waiting to be read. The rules and constraints that govern how an operation behaves are, in most cases, never expressed formally, because the informal constraints that experienced operators navigate every day emerged from experience rather than from intentional design and were never specified as rules. An operation can have thousands of these adaptations layered on top of each other, each one a constraint or dependency that has never been captured in a form a solver could reason over, and the only comprehensive record of them, however implicit, lives in the event data the operation produces, where the patterns show up in timestamps, sequences, deviations, and workarounds even when nobody has named or recognized them.
The work of turning that implicit record into explicit mathematical objects the rest of the system can depend on is what this stage calls formalization, and it is what AI does throughout. The result is a digital twin in the strict sense of the term: a single formal model of the operation, continuously updated from the operation itself, that multiple disciplines draw from simultaneously. Process discovery reads it as a workflow, simulation runs it forward to evaluate counterfactuals, and the solver layer downstream consumes it as constraints, objective terms, and parameter distributions. Digital twins, process mining, and optimization are traditionally thought of as separate disciplines, but within this framework they all operate against the same underlying formalization of what actually goes on in the operation, which is why maintaining that formalization is the central architectural concern rather than any one of the techniques that depend on it.
What makes this formalization particularly demanding in logistics is that the underlying structure has to be object-centric, because a single event touches a pallet, an order, a wave, a shipment, and an appointment simultaneously, and reducing that to a single case notion to follow would lose most of what matters. The substrate itself, however, matters less than what AI does on top of it, which is to continuously translate SOPs, operator knowledge, system field semantics, and the patterns buried in event data into the formal representations that define the optimization problem the next stage will solve.
Models & Optimization
At this point the framework has the formal structure of the decision problem, but the decision itself also depends on uncertain quantities like future demand, arrival times, and dwell durations that have not yet been observed and must be predicted. This is the work of the third stage, models and optimization, where ML models predict the uncertain quantities the operation depends on and solvers combine those predictions with the formal constraints surfaced by process intelligence to compute decisions that are optimal given both the current state of the operation and its anticipated future. The prediction techniques and solver technologies involved are well-established and have been applied in logistics for decades, but their reach has always been bounded by the cost of the formalization work required to deploy them against any given decision problem. Optimization projects in practice frequently underperform because the mathematical formulation fails to capture the business reality it is supposed to represent, which means the binding constraint on optimization's value has historically been the modeling effort rather than the algorithm. When the earlier stages of the framework reduce that effort by continuously maintaining the formal model, the threshold for which decisions are worth optimizing drops considerably, and decision problems that would never have justified a dedicated modeling engagement become tractable as a matter of course. In an industry where margins are thin enough that a few percentage points of operational efficiency determine whether a year is profitable, the cumulative effect of optimizing many individually modest decisions is substantial.
This expansion in scope also changes the distribution of good decision-making across the operation. In many logistics environments, high-quality decisions depend heavily on the undocumented judgment of experienced operators who know the local exceptions, workarounds, and capacity realities that are rarely represented in any system. A formal model of the operation, continuously maintained and connected to a solver, makes more of that knowledge structural rather than personal, reducing the extent to which decision quality depends on which planner is working or how long they have been with the company. As process intelligence surfaces new constraints and workflows over time, the formal model becomes richer and the range of decisions the system can support expands accordingly, without requiring a new implementation project for each one. The result is a broader and more consistent decision layer that improves as the operational model becomes more complete, while preserving the role of human judgment for the exceptions and tradeoffs that the formal model has not yet learned to represent.
Implementation
Most optimization value in logistics is lost between the decision and its execution. A single decision in a logistics operation typically requires coordinated action across multiple systems and people, and if that coordination falls to a human manually updating screens across different platforms, the conditions under which the decision was optimal may have changed by the time the execution is complete. This coordination problem is where optimization value has historically been lost in practice, because the system that computed the answer and the systems that need to execute it have no native connection to each other, and the human operator filling that gap is performing translation work that is both time-consuming and error-prone.
The fourth stage of Nomos, implementation, exists to bridge this gap by executing decisions through whatever systems the operation already runs, whether that means surfacing recommendations to operators, pushing decisions directly into existing platforms through integrations, or using agents to coordinate actions across multiple systems simultaneously. The right execution channel for any given decision depends on the decision type, the systems involved, and how much autonomy the operation is comfortable granting, and these can differ across decisions within the same operation at the same time. A well-constrained, high-frequency decision may execute autonomously through a direct integration while a higher-stakes decision that involves cross-functional tradeoffs is surfaced as a recommendation for a planner to evaluate, and the balance between these modes shifts over time as the formal model demonstrates its competence on specific problem types. This is what meeting the operation where it is means in concrete terms: the framework does not require the operation to replace its existing infrastructure or commit to a level of automation it is not ready for, and the scope of what executes autonomously expands as a natural consequence of the model proving itself rather than as a decision made once during deployment.
Finally, execution is where the formal model's understanding of the operation gets stress-tested against reality for the first time. A constraint that was never captured by process intelligence, a scheduling rule that exists in practice but was never formalized, a coordination dependency between systems that the model did not account for, all of these become visible when the system attempts to act on its own recommendations rather than simply presenting them. Every gap discovered through execution feeds back into the earlier stages of the framework as information about where the formal model is incomplete, which means the implementation layer functions as an active part of the system's learning rather than as the end of the pipeline, generating practical, execution-level feedback that the formal model could not have acquired from historical data alone. Whether the recommendations themselves are producing good operational outcomes, and where in the framework any failures originate, is the question the final stage is designed to answer.
Monitoring & Observability
Every recommendation the system produces or action the system takes is, in effect, a testable hypothesis about what the operation should do given the formal model's current understanding of how the operation works. The fifth stage of Nomos, monitoring and observability, exists to test those hypotheses against what actually happens, and to attribute any divergence between recommendation and outcome to the specific layer of the framework where the model's understanding was incomplete or wrong. This distinction between general performance monitoring and layer-attributed observability matters because a decision that produces a poor outcome could have failed for any number of reasons: the underlying data may have drifted, the process model may no longer reflect how the operation actually runs, a prediction may have been inaccurate, or the objective function may be optimizing for something the operation no longer cares about. Without the ability to trace a failure back to the layer that caused it, the only available response is to treat the failure as an isolated incident or to lose confidence in the system as a whole, neither of which produces the kind of structured correction that would prevent the same failure from recurring.
The most consequential form of this observability is at the decision layer, because it addresses what is arguably the central reason optimization deployments degrade over time. In conventional systems, when a planner receives a recommendation they recognize as wrong, they override it manually, the override is recorded as an undifferentiated manual intervention, and no signal from that override ever reaches the model that produced the recommendation. The system continues generating similar recommendations, the planner continues overriding them, and over time the optimization layer becomes something the operation works around rather than works with. Within Nomos, however, overrides are treated as among the most informative signals the operation produces, because each one represents a point where the formal model's understanding is demonstrably incomplete, and when the system can trace an override back to the constraint or objective term that produced the rejected recommendation and update the formulation accordingly, the failure becomes the input to its own correction. This is what makes the system's learning continuous, because every divergence between the model's understanding and reality feeds back into the formal structure so that the next round of decisions is informed by what the previous round got wrong.
Conclusion
The five stages of Nomos are facets of one continuously running system rather than five products purchased separately or five phases completed in sequence. Data infrastructure makes the operation legible, process intelligence makes it formal, models and optimization makes it decisional, implementation makes it actionable, and monitoring and observability keeps the formal model continuously corrected by the operational reality it is meant to govern. The result is what we call decisional intelligence: a platform in which every operational decision is informed by a current, formal, and faithful model of the operation that produced it, and in which every signal that the system has recommended something wrong is treated as information about how that model should evolve.